Technical proposal
for Medical File System

Technical proposal for Medical File System




Download PPTX
REST API - FHIR, GraphQL, Reactive API &
Subscriptions
We provide FHIR API, Subscriptions, GraphQL,
and SQL API. It can be extended with Custom Operations.
Service supports all major versions of FHIR: DSTU2, STU3, and R4. Strict validation ensures data consistency and integrity for all FHIR resources. With ”Subscriptions”, users can execute custom logic in their applications when specific data is changing.
GraphQL API
System supports default GraphQL implementation without any extensions. It generates different GraphQL scalars, objects, queries with args and unions from FHIR metadata.
Service supports all major versions of FHIR: DSTU2, STU3, and R4. Strict validation ensures data consistency and integrity for all FHIR resources. With ”Subscriptions”, users can execute custom logic in their applications when specific data is changing.
GraphQL API
System supports default GraphQL implementation without any extensions. It generates different GraphQL scalars, objects, queries with args and unions from FHIR metadata.


Download PPTX
REST API - FHIR, GraphQL, Reactive API &
Subscriptions
Auth Server
An authentication server is used to verify credentials when a person or another server needs to prove who they are to an application. The Auth0 Identity Platform takes a modern approach to identity and enables organizations to provide secure access to any application, for any user. Auth0 is a highly customizable platform that is as simple as development teams want, and as flexible as they need.
OpenID is an open standard and decentralized authentication protocol promoted by the non-profit OpenID Foundation. It allows users to be authenticated by co-operating sites (known as relying parties, or RP) using a third-party identity provider (IDP) service, eliminating the need for webmasters to provide their own ad hoc login systems, and allowing users to log in to multiple unrelated websites without having to have a separate identity and password for each. System has built-in OAuth 2.0 OpenID Connect server and can work as Resource Server.
An authentication server is used to verify credentials when a person or another server needs to prove who they are to an application. The Auth0 Identity Platform takes a modern approach to identity and enables organizations to provide secure access to any application, for any user. Auth0 is a highly customizable platform that is as simple as development teams want, and as flexible as they need.
OpenID is an open standard and decentralized authentication protocol promoted by the non-profit OpenID Foundation. It allows users to be authenticated by co-operating sites (known as relying parties, or RP) using a third-party identity provider (IDP) service, eliminating the need for webmasters to provide their own ad hoc login systems, and allowing users to log in to multiple unrelated websites without having to have a separate identity and password for each. System has built-in OAuth 2.0 OpenID Connect server and can work as Resource Server.
Download PPTX
REST API - FHIR, GraphQL, Reactive API &
Subscriptions
Access Control
Provides a flexible model to customize request authorization rules. User is allowed to declare a set of checks for all incoming requests. If the incoming request satisfies those checks, it's considered authorised and being processed further. Otherwise the request is denied and the client gets 403 Unauthorized. Such checks are declared with AccessPolicy resource.
Module HL7v2 / X12
Integration adapters comes with HL7 v.2 and X12 integration modules. Not all the systems that interact with modern healthcare application speak FHIR yet. Support of other interoperability standards takes a lot of burden from developers.
FHIR/Bulk API
Providing exchange data with external FHIR systems.
Provides a flexible model to customize request authorization rules. User is allowed to declare a set of checks for all incoming requests. If the incoming request satisfies those checks, it's considered authorised and being processed further. Otherwise the request is denied and the client gets 403 Unauthorized. Such checks are declared with AccessPolicy resource.
Module HL7v2 / X12
Integration adapters comes with HL7 v.2 and X12 integration modules. Not all the systems that interact with modern healthcare application speak FHIR yet. Support of other interoperability standards takes a lot of burden from developers.
FHIR/Bulk API
Providing exchange data with external FHIR systems.
Download PPTX
REST API - FHIR, GraphQL, Reactive API &
Subscriptions
Load API
Providing exchange data with external systems (any other custom formats).
Custom Resources
Resource has a type. All resource types are described with "meta-resources" - Entity and Attribute. Entity defines the resource or complex type and set of Attributes describe its structure. Not all healthcare data fits the FHIR data models. System allows adding custom resources and attributes with an easy update of metadata over RESTful API.
Providing exchange data with external systems (any other custom formats).
Custom Resources
Resource has a type. All resource types are described with "meta-resources" - Entity and Attribute. Entity defines the resource or complex type and set of Attributes describe its structure. Not all healthcare data fits the FHIR data models. System allows adding custom resources and attributes with an easy update of metadata over RESTful API.
Download PPTX
REST API - FHIR, GraphQL, Reactive API &
Subscriptions
FHIR Resources
System stores FHIR resources almost as is with 3 types of isomorphic transformations:
Union (Choice) Types: some elements can have multiple types.
First-Class Extensions - while FHIR uses two different ways to define core elements and extensions, System provides unified framework to describe both. It supports user-defined attributes or "first-class extensions". So, can define new attributes (elements) for existing (FHIR) resources.
System stores FHIR resources almost as is with 3 types of isomorphic transformations:
- References
- Union (Choice Types)
- First-Class Extensions
Union (Choice) Types: some elements can have multiple types.
First-Class Extensions - while FHIR uses two different ways to define core elements and extensions, System provides unified framework to describe both. It supports user-defined attributes or "first-class extensions". So, can define new attributes (elements) for existing (FHIR) resources.
Download PPTX
REST API - FHIR, GraphQL, Reactive API &
Subscriptions
Subscriptions
This module is a way to subscribe and get notifications about updating resources on the server. It is a common denominator of FHIR R4/R5 subscriptions specification with some extensions.
This module introduces two new resources into System:
SDKs
System integrates quickly and easily with an SDK that supports your development team's language of choice.
This module is a way to subscribe and get notifications about updating resources on the server. It is a common denominator of FHIR R4/R5 subscriptions specification with some extensions.
This module introduces two new resources into System:
- SubsSubscription — meta-resource which binds events (create/update/delete resource) with a communication channel through which subscriber is notified about changes.
- SubsNotification — resource which represents notification with its status (sent or not).
SDKs
System integrates quickly and easily with an SDK that supports your development team's language of choice.
Download PPTX
REST API - FHIR, GraphQL, Reactive API &
Subscriptions
Audit
System automatically logs all auth, API, database and network events, so in most cases basic audit log may be derived from System logs. FHIR Standard introduced AuditEvent resource which into FHIR ecosystem. System provides comprehensive FHIR API for AuditEvent resource.
Terminology
System terminology comes with FHIR, ICD-10, SNOMED, RxNorm, LOINC, and US NPI. Users can extend it with other terminologies and custom value sets.
System automatically logs all auth, API, database and network events, so in most cases basic audit log may be derived from System logs. FHIR Standard introduced AuditEvent resource which into FHIR ecosystem. System provides comprehensive FHIR API for AuditEvent resource.
Terminology
System terminology comes with FHIR, ICD-10, SNOMED, RxNorm, LOINC, and US NPI. Users can extend it with other terminologies and custom value sets.
Download PPTX

Database
FHIR-aware PostgreSQL with SQL on FHIR
support System uses PostgreSQL exclusively but squeezes everything out of this database
technology. Most of System flexibility and performance is coming from advanced PostgreSQL
features like binary JSON, rich indexing system, etc. SQL is the second System API, which
gives you extra power on structured data.




Download PPTX

Real-time integration pipeline
Export while importing data from CCDA
documents, there are many nuances on every step. How does your system receive CCDA
documents? What data elements do you want to persist? How would your system deduplicate
patient records?
Because answers to those questions are strictly system-specific, System does not provide a ready-to-use solution here. But we can implement new pipeline, using any favourite technology stack.
Because answers to those questions are strictly system-specific, System does not provide a ready-to-use solution here. But we can implement new pipeline, using any favourite technology stack.

Download PPTX
Receiving CCDA files
The first step is to understand how System
would receive CCDA files. In case when we have an user-facing application like Patient
Portal or EHR user will upload his CCDA file manually. The other common case is bulk import
from remote storage like SFTP server or S3 bucket.
Processing received files is usually a resource consuming task, so it’s better to make it asynchronous. This way our system would be responsive while the file is being converted, and the entire conversion process would be much more manageable. For example, we may notice a bug in the CCDA converting logic, our engineers will fix it and we would like to process all recently received files. Holding all received files in a queue will give you this ability.
There are dozens of ways to set up such a queue, probably the most simple one is to use the DocumentReference resource (if we know a patient to whom this document belongs). Alternatively we can use a dedicated queue service like Apache Kafka or just a custom table in our RDBMS. However, despite the storage we would use, we would store the original CCDA file to be able to access it at any time.
On the next step some kind of background job or a worker will pick received files from a queue and process them one after another.
Processing received files is usually a resource consuming task, so it’s better to make it asynchronous. This way our system would be responsive while the file is being converted, and the entire conversion process would be much more manageable. For example, we may notice a bug in the CCDA converting logic, our engineers will fix it and we would like to process all recently received files. Holding all received files in a queue will give you this ability.
There are dozens of ways to set up such a queue, probably the most simple one is to use the DocumentReference resource (if we know a patient to whom this document belongs). Alternatively we can use a dedicated queue service like Apache Kafka or just a custom table in our RDBMS. However, despite the storage we would use, we would store the original CCDA file to be able to access it at any time.
On the next step some kind of background job or a worker will pick received files from a queue and process them one after another.




Check out our healthtech expertise
Select projects we have made for the industry
giants
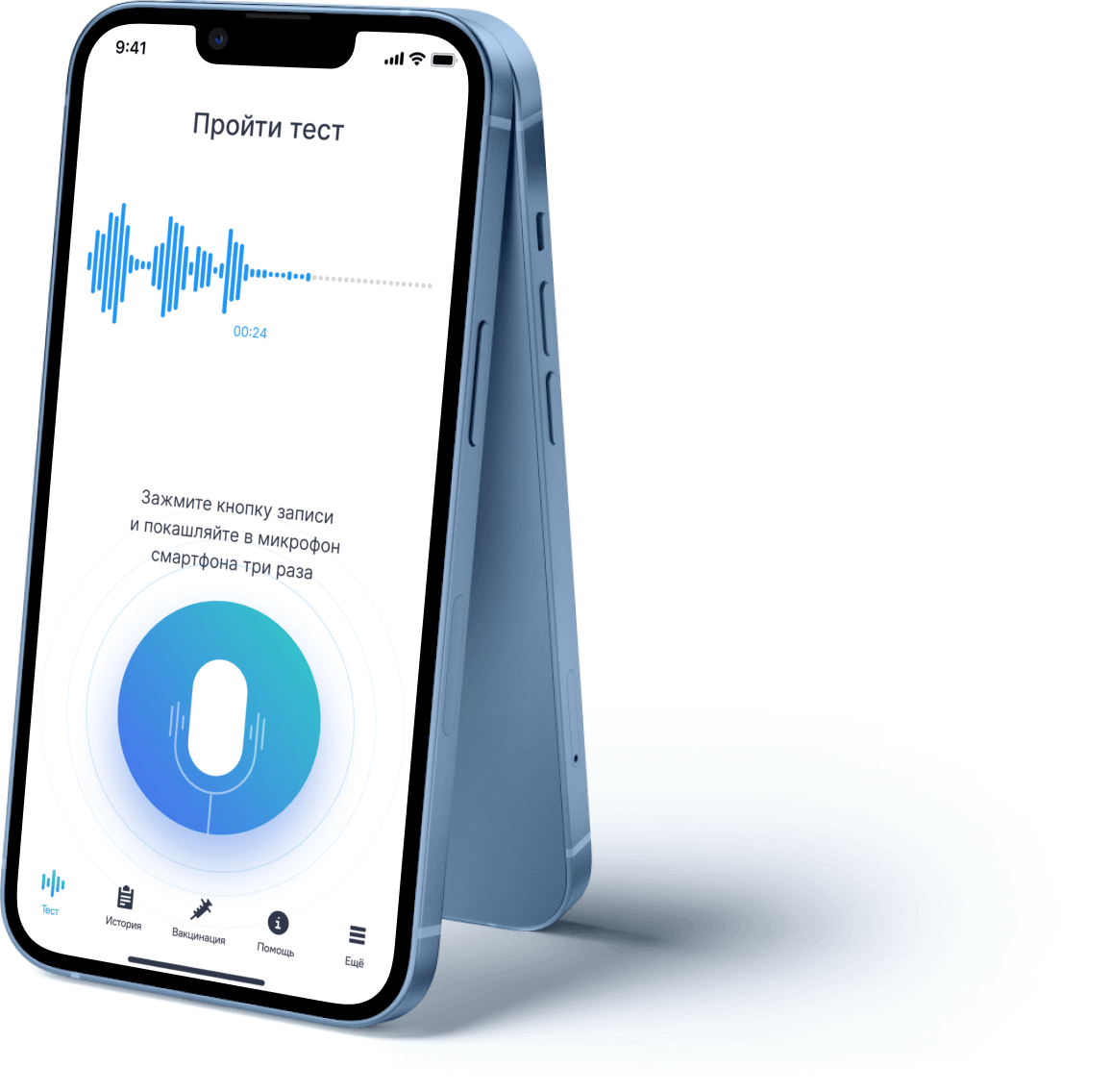
Timely and efficient diagnostic became one of
the ways to prevent the COVID-19 infection spread.PCR tests show whether the carrier is
infected and proved to be inefficient in 30-40% in field testing and even in lab testing. It
is also non-instant, uncomfortable and costly. Temperature screening with handheld devices
is easy but inaccurate and detects only a fever, not the infection and useless in
asymptomatic cases. The user just coughs in the microphone of any smartphone a few times for
instant result provided by neural network. We use ML (machine learning) algorithms to detect
the COVID19 specific resonance in vocal sounds (coughing, speaking, etc.). This make field
screening instant, non-invasive, supplies free.
Project owner: Sunset Systems LLC
Type Of Project: MedTech
2020 → 2021
Type Of Project: MedTech
2020 → 2021

Archived project
Check out our healthtech expertise
Select projects we have made for the industry
giants
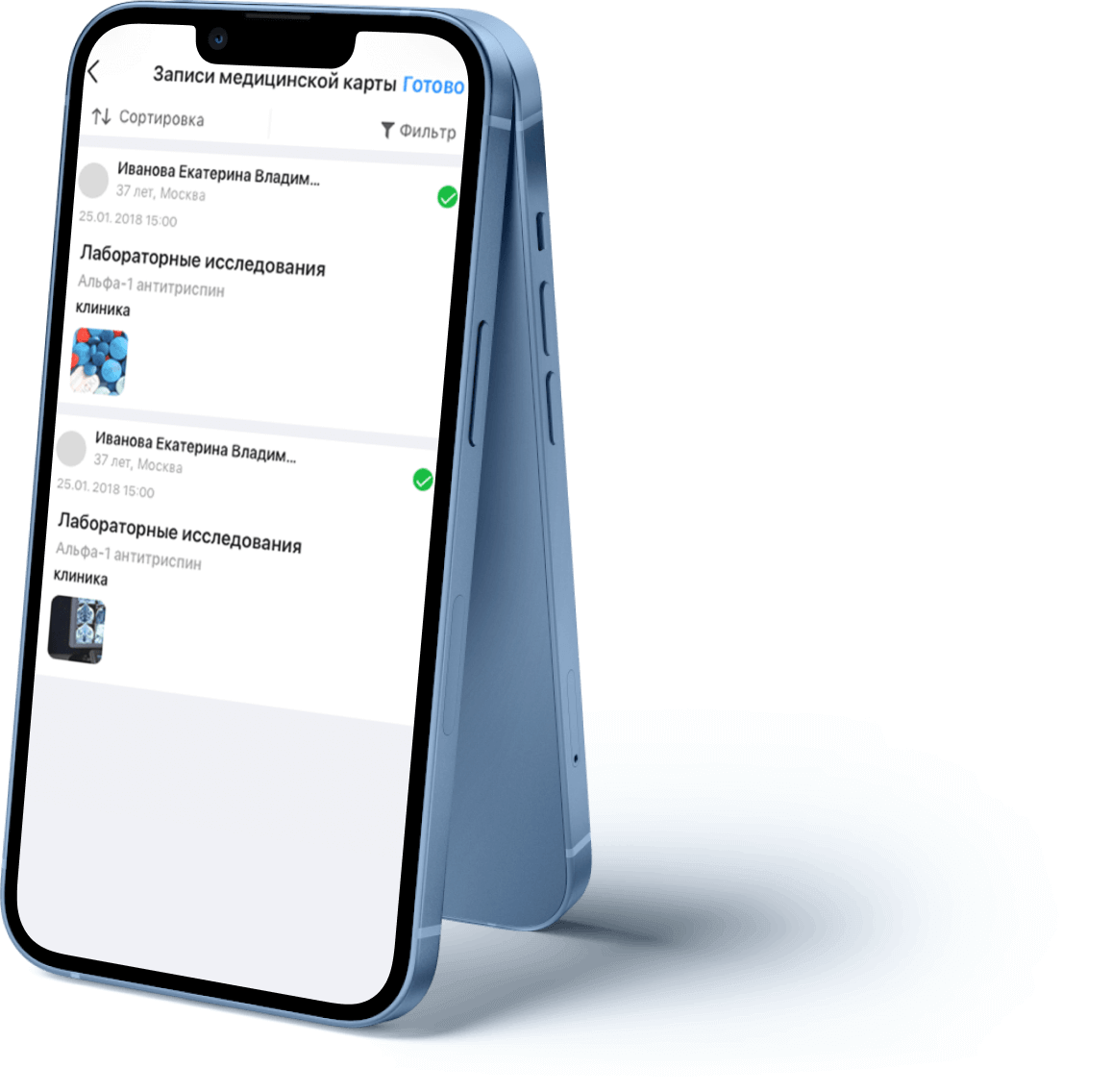
Application "Med.One Specialists" - helps to
create a virtual registry, have instant access to medical records of patients, respond to
their complaints in a timely manner and give recommendations for
treatment.
Application "Med.One Patients" - helps to organize a personal electronic medical record with statements and analyzes in one place and receive treatment recommendations from the attending physician.
Application "Med.One Patients" - helps to organize a personal electronic medical record with statements and analyzes in one place and receive treatment recommendations from the attending physician.
Project owner: Med.One LLC
Type Of Project: MedTech
2018 → 2018
Type Of Project: MedTech
2018 → 2018

Check out our healthtech expertise
Select projects we have made for the industry
giants
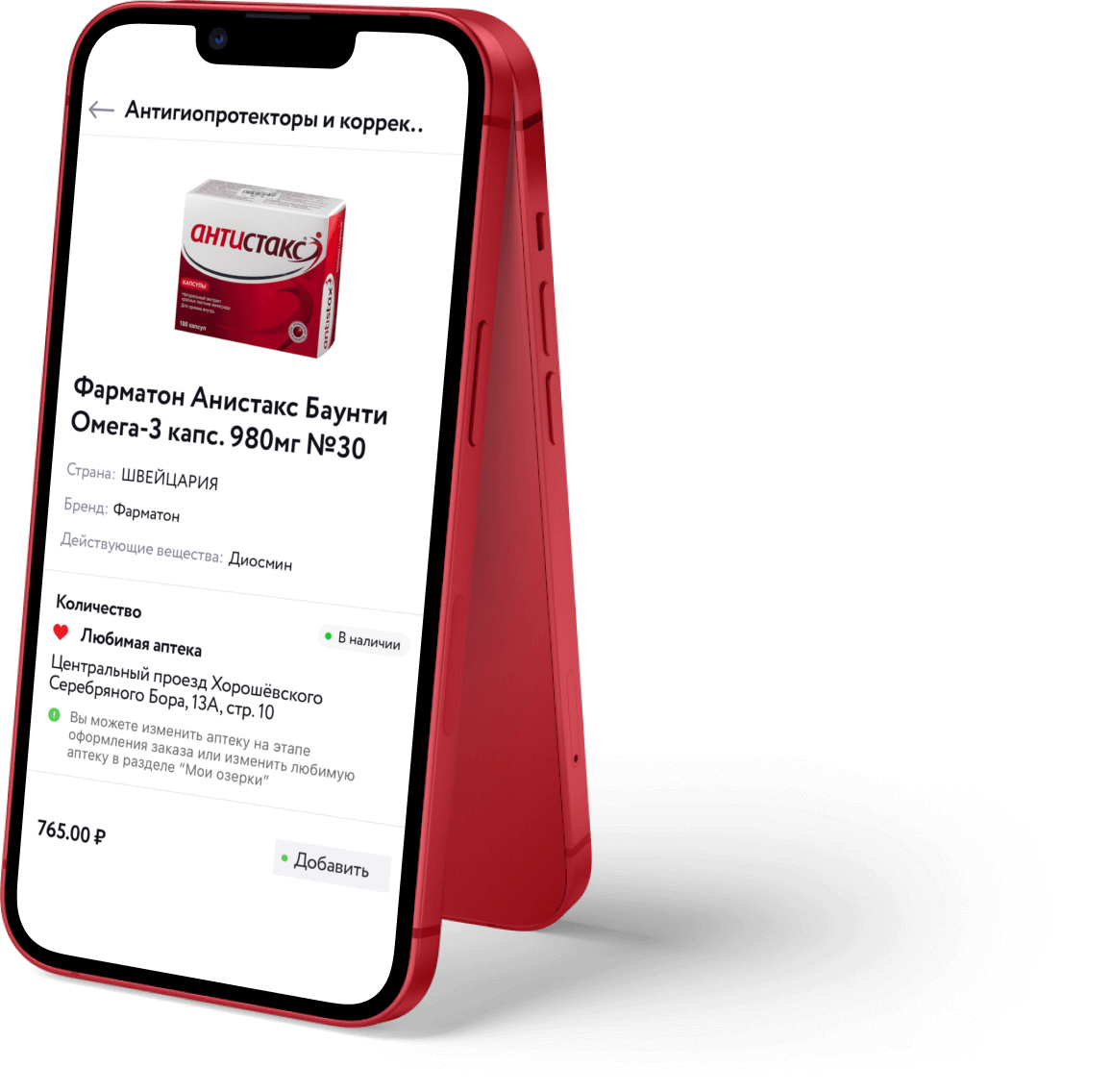
Ozerki is the largest discounter pharmacy
chain in Russia and one of the largest chains in terms of the number of visitors served.
Since 2014, it has been part of the ERKAFARM group of companies, one of the leaders in the
Russian pharmaceutical market.
The Ozerki Pharmacy app is a service for quickly finding and ordering medicines and health and beauty products at the nearest pharmacy.
The Ozerki Pharmacy app is a service for quickly finding and ordering medicines and health and beauty products at the nearest pharmacy.
Project owner: ERKAFARM JSC
Type Of Project: MedTech
2018 → 2018
Type Of Project: MedTech
2018 → 2018



Check out our healthtech expertise
Select projects we have made for the industry
giants
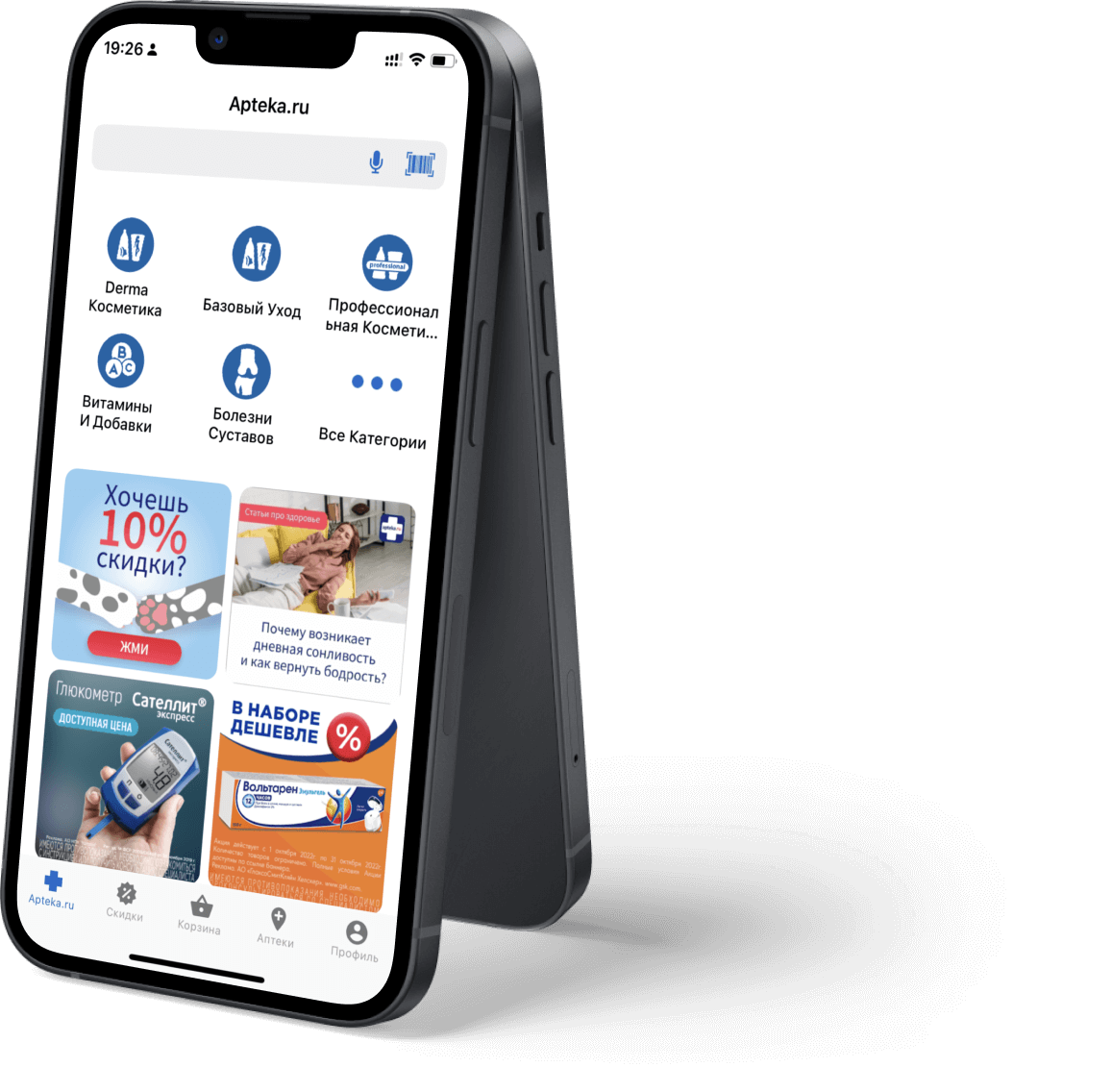
Apteka.RU is a federal online service for
ordering pharmacy products, a project of Katren, Russia's leading pharmaceutical
distributor.
The Apteka.RU application is designed to quickly search for and order medicines and health and beauty products on the website of the largest Russian online drug retailer apteka.ru
The Apteka.RU application is designed to quickly search for and order medicines and health and beauty products on the website of the largest Russian online drug retailer apteka.ru
Project owner: Katren JSC NPK
Type Of Project: MedTech
2015 → 2016
Type Of Project: MedTech
2015 → 2016

Check out our healthtech expertise
Select projects we have made for the industry
giants
Сompact screener for measuring intraocular
pressure and early detection of glaucoma, allows for mass medical examinations without the
use of expensive stationary equipment.
Project owner: Sunset Systems LLC
Type Of Project: MedTech
2018 → 2020
Type Of Project: MedTech
2018 → 2020

Check out our healthtech expertise
Select projects we have made for the industry
giants
Exogenous nitrogen monoxide generator. The
discovery of the signaling function of nitric oxide received the Nobel Prize in Medicine in
1998.
It is used in various fields of surgery, sports medicine, prevention and others, several dozen methods have been developed.
It is used in various fields of surgery, sports medicine, prevention and others, several dozen methods have been developed.
Project owner: Sunset Systems LLC
Type Of Project: MedTech
2016 → 2019
Type Of Project: MedTech
2016 → 2019


Check out our healthtech expertise
Select projects we have made for the industry
giants
The insurance company "HEALTH" provides
services for solving financial problems in the territory of Kyrgyzstan. One of the company’s
insurance activities is medical (life and health insurance).
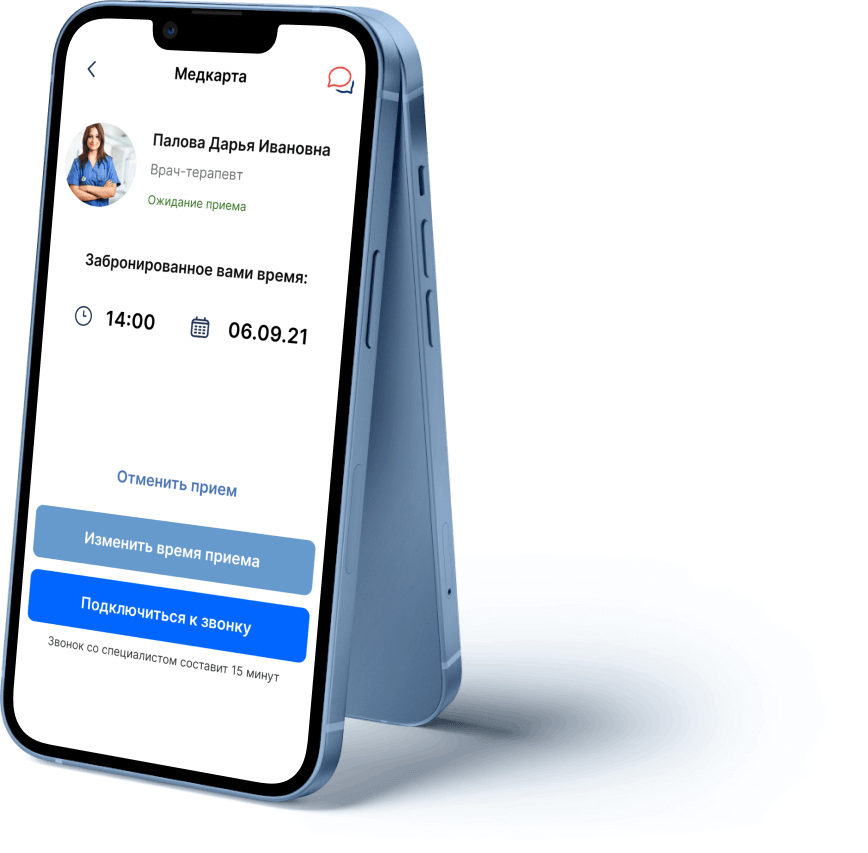
The application "My Doctor" is a medical assistant with which you do not have to stand in queues at the clinic, adjust to the doctor’s schedule, pay each time for an appointment. The application offers a convenient choice of a doctor by rating for a video call, saves all medical information in a personal card, and helps to choose laboratories and clinics.
The application "My Doctor" is a medical assistant with which you do not have to stand in queues at the clinic, adjust to the doctor’s schedule, pay each time for an appointment. The application offers a convenient choice of a doctor by rating for a video call, saves all medical information in a personal card, and helps to choose laboratories and clinics.
Project owner: Health CJSC
Type Of Project: MedTech
2018 → 2022
Continued regular updates and improvements
Type Of Project: MedTech
2018 → 2022
Continued regular updates and improvements

Check out our healthtech expertise
Select projects we have made for the industry
giants
DiabetAdvisor is your personal
endocrinologist. An indispensable app for people with diabetes. The service allows to
communicate online with a doctor. You will be consulted by the best specialists with
extensive experience
Project owner: Omega Medical Group RUS
LTD.
2016
2016


Check out our integration expertise
Select projects we have made for the industry
giants
Open Broker is a leading Russian brokerage
firm. Member of the Otkrytiye group.
A personalized mobile dashboard for Open Broker clients with improved design and interface. Clients can use the app to view the status of their brokerage accounts, transfer funds, make deals, and more.
A personalized mobile dashboard for Open Broker clients with improved design and interface. Clients can use the app to view the status of their brokerage accounts, transfer funds, make deals, and more.
Project owner: Open Broker JSC
Type Of Project: Investments
2017 → 2022
Continued regular updates and improvements
Type Of Project: Investments
2017 → 2022
Continued regular updates and improvements

Archived project
Check out our integration expertise
Select projects we have made for the industry
giants
Sberbank Leasing was the first leasing
company in Russia to offer clients the option of electronic contract signatures. Sberbank
Leasing belongs to Russia's largest banking group, Sberbank. The European organization
Leaseurope rated Sberbank Leasing among Europe's top 20 leasing companies and placed it at
the top of their list for Russia.
The Sberbank Leasing app gives clients easy access to promotional programs and special deals for leasing automobiles, machines, and specialized equipment.
The Sberbank Leasing app gives clients easy access to promotional programs and special deals for leasing automobiles, machines, and specialized equipment.
Project owner: Sberbank Leasing JSC
Type Of Project: Banking and finance
2017 → 2018
Type Of Project: Banking and finance
2017 → 2018

Archived project
Check out our integration expertise
Select projects we have made for the industry
giants
RN Bank - Bank Alliance
Renault-Nissan-Mitsubishi.
The RN Bank app keeps RN Bank clients up to date on information regarding their loan payments.
The app’s design was developed in collaboration with Art. Lebedev Studio.
The RN Bank app keeps RN Bank clients up to date on information regarding their loan payments.
The app’s design was developed in collaboration with Art. Lebedev Studio.
Project owner: RN Bank JSC
Type Of Project: Banking and finance
2017 → 2022
Continued regular updates and improvements
Type Of Project: Banking and finance
2017 → 2022
Continued regular updates and improvements


Check out our integration expertise
Select projects we have made for the industry
giants
Rosgosstrakh is Russia's one off largest and
most influential insurance company. The Rosgosstrakh app provides a personal dashboard for
current and potential clients of the insurance company Rosgosstrakh PJSC.
Project owner: Rosgosstrakh Insurance Company
(PJSC)
Type Of Project: Insurance
2015 → 2018
New Version in 2020
Type Of Project: Insurance
2015 → 2018
New Version in 2020

Archived project
Check out our integration expertise
Select projects we have made for the industry
giants
SOGAZ is a leading Russian insurance company
and head of the SOGAZ Insurance Group. For the 8th consecutive year, SOGAZ is the 2nd
largest insurance company in Russia by total insurance premiums.
The SOGAZ app provides a personal dashboard for current and potential clients of SOGAZ JSC. Clients can use the app to track policy information and purchase insurance policies.
The SOGAZ app provides a personal dashboard for current and potential clients of SOGAZ JSC. Clients can use the app to track policy information and purchase insurance policies.
Project owner: SOGAZ JSС
Type Of Project: Insurance
2018 → 2019
Type Of Project: Insurance
2018 → 2019

Archived project
Check out our integration expertise
Select projects we have made for the industry
giants
Capital Health Insurance is the largest
health insurance company in Russia. Their aim is to defend the rights and legal interests of
mandatory medical insurance claim holders.
Capital Health Insurance is a universal assistant for holders of mandatory medial insurance claims.
Capital Health Insurance is a universal assistant for holders of mandatory medial insurance claims.
Project owner: Rosgosstrakh Insurance Company
(PJSC)
Type Of Project: Insurance
2017 → 2019
Type Of Project: Insurance
2017 → 2019

ДМС
Archived project
Check out our integration expertise
Select projects we have made for the industry
giants
My ROLF personal account offers quick online
signup, service/repair completion notification, service/repair history, and recommendations.
Project owner: ROLF LLC
Type Of Project: E-commerce
2017 → 2022
Continued regular updates and improvements
Type Of Project: E-commerce
2017 → 2022
Continued regular updates and improvements

Check out our integration expertise
Select projects we have made for the industry
giants
Project owner: VTB PJSC
Type Of Project: Banking and finance
2017 → 2018
Type Of Project: Banking and finance
2017 → 2018
VTB Bank is a universal bank with partial
government ownership. It is the second bank in Russia by number of assets owned and first by
amount of authorized capital. On January 1st, 2018 VTB Bank acquired the subsidiary VTB24.
We were responsible the seamless integration of their banking systems and
applications.
The VTB Online app provides a fully-fledged mobile bank for every VTB Bank client.
The VTB Online app provides a fully-fledged mobile bank for every VTB Bank client.

Archived project
Check out our integration expertise
Select projects we have made for the industry
giants
Project owner: FxPro FSL
Type Of Project: Investments
2018 → 2022
Continued regular updates and improvements
Type Of Project: Investments
2018 → 2022
Continued regular updates and improvements

FxPro Financial Services Limited is a
brokerage firm. Finance Magnates ranked FxPro among the world's TOP 10 largest retail
brokers.
FxPro Direct is an app designed for trading on financial markets, and meets all the demands of traders.
FxPro Direct is an app designed for trading on financial markets, and meets all the demands of traders.

Check out our integration expertise
Select projects we have made for the industry
giants
Project owner: OTP Bank JSC
Type Of Project: Banking and finance
2018 → 2019
Type Of Project: Banking and finance
2018 → 2019

OTP Loan app provides all payment information
for retail loans (originated at POS) right on the user’s phone – quick, simple, convenient.

Archived project
Sunset Systems is the same age as the mobile
application industry
Sunset Systems was established in 2008 and
specializes on the development of financial technology. Our primary focus is on mobile apps,
server solutions, integration, and web sites.
In the past 14 years, we have seen over 164
projects through to completion. Our clients have included leading businesses all over the
world.
>100 M

>111

164 apps

4 offices
>200



>14 years
In business
Professionals
Developed
Mobile app users
Corporate clients
Worldwide
Mobile app users
>100 M
Corporate clients
>111
Developed
164 apps
Worldwide
4 offices
Professionals
>200
In business
> 14 years
Den Khoruzhiy
PhD. CTO
10+ years experience as a technical
director.
PhD in Physics and Mathematics.
Experience in Machine Learning, Natural language processing.
PhD in Physics and Mathematics.
Experience in Machine Learning, Natural language processing.
Eugene Ivanov
PM Lead
9 years experience, managing team with back-end and
front-end developers, product designers, DevOps and QA engineers.
Boris Shmarkovsky
Senior VP Business Development
20+ years experience in IT and FinTech, Head of IT
Development at NikOil, MENATEP, ROSBANK, CIO InterProgressBank.
FOLLOW US ON SOCIAL MEDIA TO SEE OUR LATEST
PROJECTS
